-
2023/11/29/用户新增预测挑战赛-特征工程/
任务2.3:特征工程
特征工程指的是把原始数据转变为模型训练数据的过程,目的是获取更好的训练数据特征。特征工程能使得模型的性能得到提升,有时甚至在简单的模型上也能取得不错的效果。
# 1. 导入需要用到的相关库
import pandas as pd
import numpy as np
import matplotlib as plt
import seaborn as sns
# 导入模型
from sklearn.linear_model import SGDClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.naive_bayes import MultinomialNB
from sklearn.ensemble import RandomForestClassifier
# 导入交叉验证和评价指标
from sklearn.model_selection import cross_val_predict
from sklearn.metrics import classification_report
# 2. 读取训练集和测试集文件
train_data = pd.read_csv('用户新增预测挑战赛公开数据/train.csv')
test_data = pd.read_csv('用户新增预测挑战赛公开数据/test.csv')
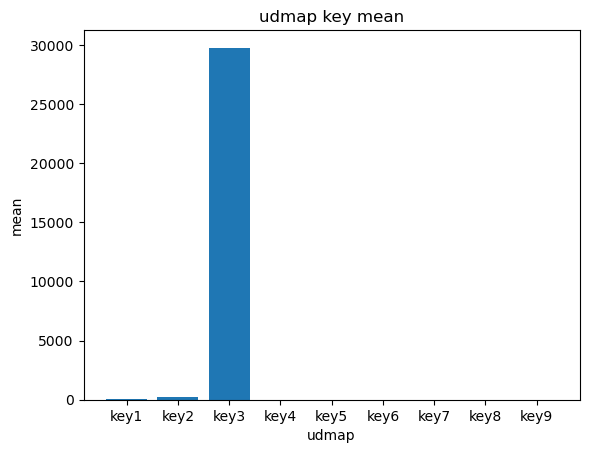
# 提取udmap特征,人工进行onehot
def udmap_onethot(d):
v = np.zeros(9)
if d == 'unknown':
return v
d = eval(d)
for i in range(1, 10):
if 'key' + str(i) in d:
v[i-1] = d['key' + str(i)]
return v
train_udmap_df = pd.DataFrame(np.vstack(train_data['udmap'].apply(udmap_onethot)))
test_udmap_df = pd.DataFrame(np.vstack(test_data['udmap'].apply(udmap_onethot)))
train_udmap_df.columns = ['key' + str(i) for i in range(1, 10)]
test_udmap_df.columns = ['key' + str(i) for i in range(1, 10)]
# 编码udmap是否为空
train_data['udmap_isunknown'] = (train_data['udmap'] == 'unknown').astype(int)
test_data['udmap_isunknown'] = (test_data['udmap'] == 'unknown').astype(int)
# udmap特征和原始数据拼接
train_data = pd.concat([train_data, train_udmap_df], axis=1)
test_data = pd.concat([test_data, test_udmap_df], axis=1)
# 提取eid的频次特征
train_data['eid_freq'] = train_data['eid'].map(train_data['eid'].value_counts())
test_data['eid_freq'] = test_data['eid'].map(train_data['eid'].value_counts())
# 提取eid的标签特征
train_data['eid_mean'] = train_data['eid'].map(train_data.groupby('eid')['target'].mean())
test_data['eid_mean'] = test_data['eid'].map(train_data.groupby('eid')['target'].mean())
# 提取时间戳
train_data['common_ts'] = pd.to_datetime(train_data['common_ts'], unit='ms')
test_data['common_ts'] = pd.to_datetime(test_data['common_ts'], unit='ms')
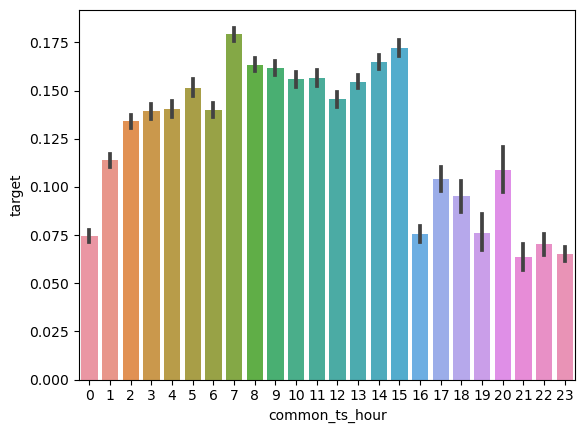
train_data['common_ts_hour'] = train_data['common_ts'].dt.hour
test_data['common_ts_hour'] = test_data['common_ts'].dt.hour# 3. 进行特征工程
train_data['common_ts_day'] = train_data['common_ts'].dt.day
test_data['common_ts_day'] = test_data['common_ts'].dt.day
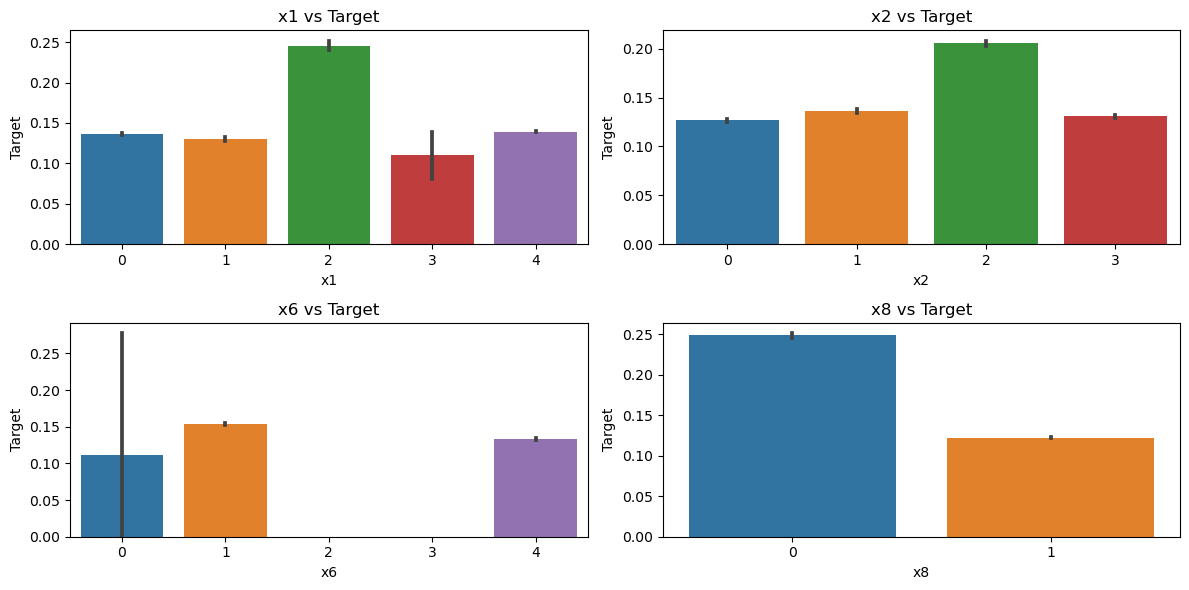
train_data['x1_freq'] = train_data['x1'].map(train_data['x1'].value_counts())
test_data['x1_freq'] = test_data['x1'].map(train_data['x1'].value_counts())
train_data['x1_mean'] = train_data['x1'].map(train_data.groupby('x1')['target'].mean())
test_data['x1_mean'] = test_data['x1'].map(train_data.groupby('x1')['target'].mean())
train_data['x2_freq'] = train_data['x2'].map(train_data['x2'].value_counts())
test_data['x2_freq'] = test_data['x2'].map(train_data['x2'].value_counts())
train_data['x2_mean'] = train_data['x2'].map(train_data.groupby('x2')['target'].mean())
test_data['x2_mean'] = test_data['x2'].map(train_data.groupby('x2')['target'].mean())
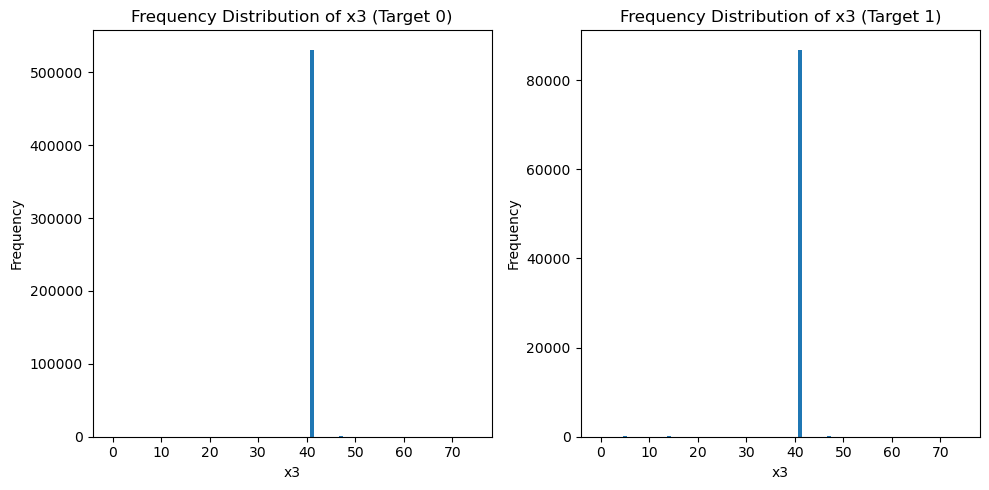
train_data['x3_freq'] = train_data['x3'].map(train_data['x3'].value_counts())
test_data['x3_freq'] = test_data['x3'].map(train_data['x3'].value_counts())
train_data['x4_freq'] = train_data['x4'].map(train_data['x4'].value_counts())
test_data['x4_freq'] = test_data['x4'].map(train_data['x4'].value_counts())
train_data['x6_freq'] = train_data['x6'].map(train_data['x6'].value_counts())
test_data['x6_freq'] = test_data['x6'].map(train_data['x6'].value_counts())
train_data['x6_mean'] = train_data['x6'].map(train_data.groupby('x6')['target'].mean())
test_data['x6_mean'] = test_data['x6'].map(train_data.groupby('x6')['target'].mean())
train_data['x7_freq'] = train_data['x7'].map(train_data['x7'].value_counts())
test_data['x7_freq'] = test_data['x7'].map(train_data['x7'].value_counts())
train_data['x7_mean'] = train_data['x7'].map(train_data.groupby('x7')['target'].mean())
test_data['x7_mean'] = test_data['x7'].map(train_data.groupby('x7')['target'].mean())
train_data['x8_freq'] = train_data['x8'].map(train_data['x8'].value_counts())
test_data['x8_freq'] = test_data['x8'].map(train_data['x8'].value_counts())
train_data['x8_mean'] = train_data['x8'].map(train_data.groupby('x8')['target'].mean())
test_data['x8_mean'] = test_data['x8'].map(train_data.groupby('x8')['target'].mean())# 准备特征矩阵 X 和目标向量 y
X = train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1)
y = train_data['target']
# 训练决策树模型
dt_model = DecisionTreeClassifier()
dt_model.fit(X, y)
# 获取特征重要性
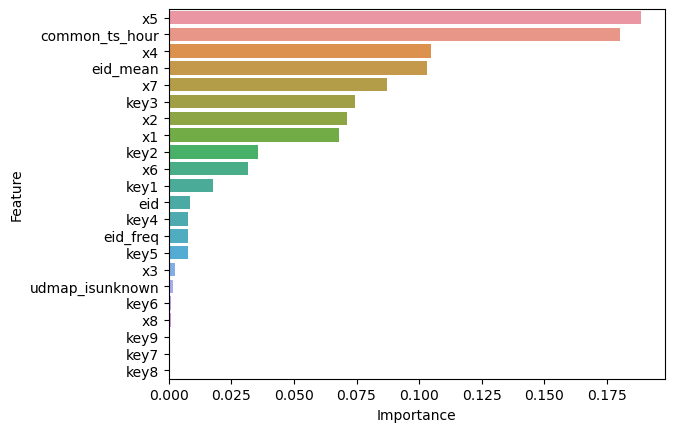
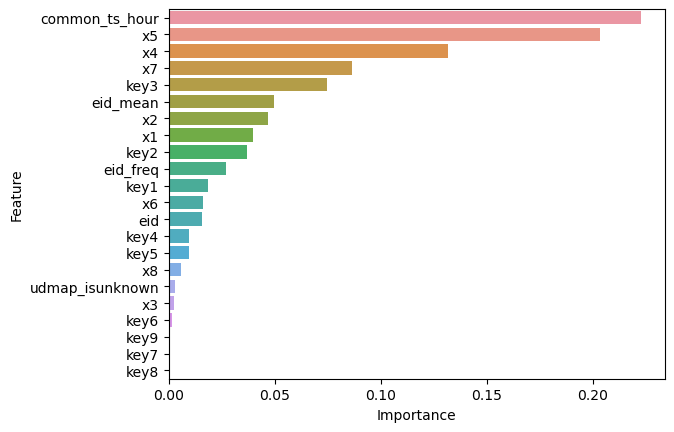
feature_importance = dt_model.feature_importances_
# 创建一个包含特征名称和其重要性值的DataFrame
importance_df = pd.DataFrame({'Feature': X.columns, 'Importance': feature_importance})
# 按照重要性值降序排序
importance_df = importance_df.sort_values(by='Importance', ascending=False)
# 可视化特征重要性
sns.barplot(x='Importance', y='Feature', data=importance_df)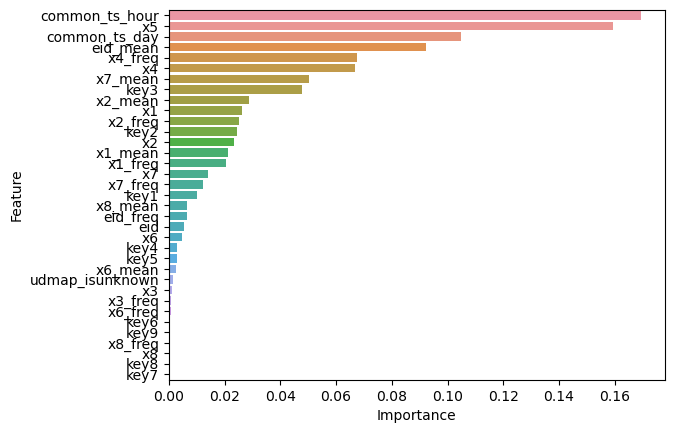
# 训练并验证DecisionTreeClassifier
pred = cross_val_predict(dt_model, X, y)
print(classification_report(y, pred, digits=3)) precision recall f1-score support
0 0.955 0.951 0.953 533155
1 0.707 0.726 0.717 87201
accuracy 0.919 620356
macro avg 0.831 0.839 0.835 620356
weighted avg 0.920 0.919 0.920 620356
- 加入特征之后模型的精度有什么变化?
交叉验证f1-score从0.771提升到0.835。
- 思考并加入3个额外的特征,并观测模型精度的变化
Author: Siyuan
URL: https://siyuan-zou.github.io/2023/11/29/%E7%94%A8%E6%88%B7%E6%96%B0%E5%A2%9E%E9%A2%84%E6%B5%8B%E6%8C%91%E6%88%98%E8%B5%9B-%E7%89%B9%E5%BE%81%E5%B7%A5%E7%A8%8B/
This work is licensed under a CC BY-SA 4.0 .